

Edoardo Barbieri
on 30 October 2025
On October 23rd, we announced the beta availability of silicon-optimized AI models in Ubuntu. Developers can locally install DeepSeek R1 and Qwen 2.5 VL with a single command, benefiting from maximized hardware performance and automated dependency management.
Application developers can access the local API of a quantized generative AI (GenAI) model with runtime optimizations for efficient performance on their CPU, GPU, or NPU.
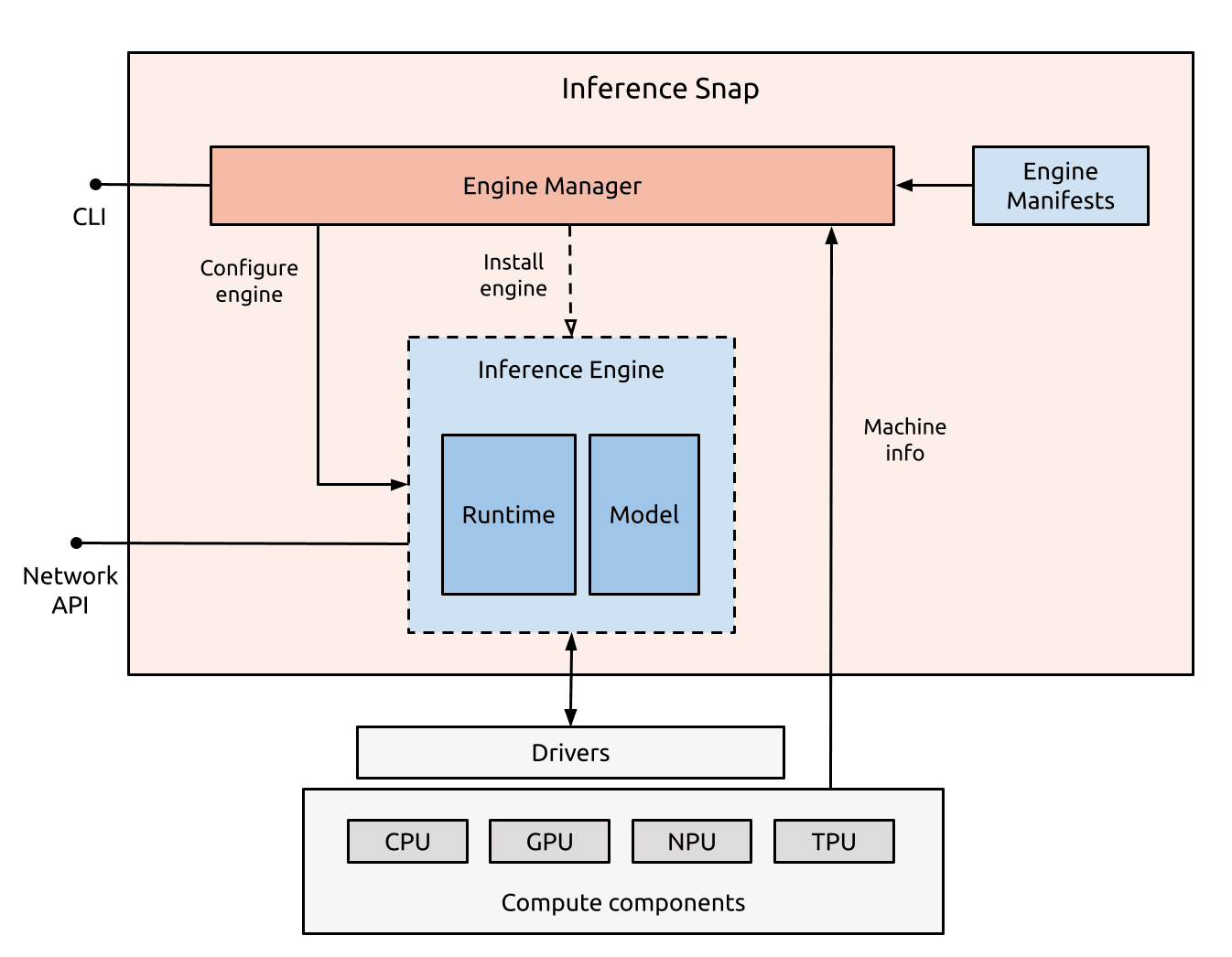
Architecture of the new open-source tool enabling developers to bundle different combinations of runtimes and weights into a single snap, deploying the most optimal stack on the host machine
By meeting developers at the intersection of silicon and GenAI models, we package, distribute and manage all the necessary components to run AI apps on any machine that runs Ubuntu. Developers can now install pre-trained and fine-tuned AI models that automatically detect the underlying silicon requirements, from how much memory and what GPU or NPU they need, to which software components and default configurations must be included.
What’s the vision behind the announcement, and how did we pull it off?
Ubuntu: the standard distribution platform for AI models
We aim to make Ubuntu the standard distribution platform for generative AI models. Doing so will enable developers to integrate AI seamlessly into their applications and run them optimally across desktops, servers, and edge devices. We believe machine learning (ML) workloads will soon be as fundamental to compute platforms as traditional software dependencies are today, and generative AI models will be a basic part of the compute experience.
But wait: isn’t that already true? Aren’t AI models already everywhere, and don’t we all play with LLMs around 25 times per day?
Yes, but there’s a key distinction. Let me use an analogy to illustrate it.
From fragmentation to curated archives of software
In the early days of Linux, software distribution was fragmented and cumbersome. Developers had to manually download, compile, and configure source code from individual projects, often tracking down missing libraries, resolving version conflicts, and maintaining complex build environments by hand.

While in the early 90s, software was distributed via floppy disks, Slackware and Debian Linux soon ushered in a system of curated archives of software, usually pre-compiled to save time. Source: https://www.debian.org/
As each distribution had its own conventions, packaging tools, and repositories, installing software was an error-prone and time-consuming process. The lack of a unified delivery mechanism slowed down open-source development and created barriers to adoption.

In October 2004, the first release of Ubuntu was out. It shipped with a fairly fixed set of packages in the Ubuntu archive, for which users received security updates and bug fixes over the internet. To get new software, developers still had to hunt down source code and compile it themselves.
What changed?
Fast-forward to a few years later, and in 2007, Canonical introduced Personal Package Archives (PPA), giving developers a hosted build service to publish and share their own software. Discovering new software on Linux was still hard, from living in unknown PPAs to GitHub repositories with daily builds of all kinds of new software. To fix this, Canonical later introduced snaps, containerized software packages that simplified cross-distribution delivery, updates and security.
Standing on the shoulders of giants and building on Debian, Ubuntu helped transform that experience, becoming the aggregation point for open-source software (OSS). Ubuntu consolidated thousands of upstream projects into a coherent, trusted ecosystem that developers could rely on, without needing to understand every dependency or build chain behind it. Ubuntu helped unify and streamline the open-source ecosystem.
A strong packaging foundation, combined with a steady release cadence and curated repositories, lowered the barrier for both developers and enterprises. Ubuntu became the default, trusted layer for distributing and maintaining open-source software.
What if we could do that with AI models?
GenAI models as basic building blocks of future compute
Today, software packages are the basic building blocks of compute. Developers routinely install packages, add PPAs, and pull from various vendors, third parties, or the community, without giving it much thought.
We believe that AI models will soon occupy the same space as first-class citizens of a compute stack. They’ll be treated as standard system components, installed, updated and optimized just like any other dependency. We’ll no longer worry about the details of how to juggle the dependencies of various AI models, just as we don’t think about which repositories the packages your projects depend on come from. Developing software will naturally include integrating ML workloads, and models will be as ubiquitous and invisible in the developer experience as traditional packages are today. LLMs will become part of the commodity layer of compute, evolving into dependencies that containerized workloads rely on: composable, versioned, and hardware-optimized.
In making Ubuntu, we mastered the art of distributing open-source software to millions of users. Now we are applying that expertise to AI model distribution. Ubuntu is moving toward making AI models a native element of the compute environment. We’re shifting AI models from external tools to an integral part of the stack. Bringing silicon-optimized AI models natively to Ubuntu is the first step in making them a built-in component of the compute experience itself.
What are silicon-optimized models?
In the announcement, we introduced Intel and Ampere – optimized DeepSeek R1 and Qwen VL, two leading examples of Generative AI models.
DeepSeek R1 is a reasoning Large Language Model (LLM) designed to decompose prompts into structured chains of thought, enabling complex reasoning and problem solving. Qwen VL, on the other hand, is a multimodal LLM that accepts both text and images as inputs, representing the latest generation of vision-language models. Both are transformer-based but tuned and packaged to exploit different runtime patterns and hardware characteristics.
Let’s be more specific. The term model is often used loosely, but in practice, it refers to an entire model family built around a base model. Base models are massive neural networks trained on broad datasets to capture general knowledge. These base models are frequently fine-tuned, retrained, or adapted to specialize in specific tasks, such as instruction following or domain-specific reasoning. For instance, transformer-based LLMs share a common architecture built on components such as self-attention, multi-head attention, and large embedding matrices. From this base, families of foundational models and fine-tuned derivatives, such as instruction-tuned models, adapter-based variants, or task-specific fine-tunes, can be developed.
Inference with fine-tuned models
Let’s look at an example of some of the Mistral models from Mistral AI.
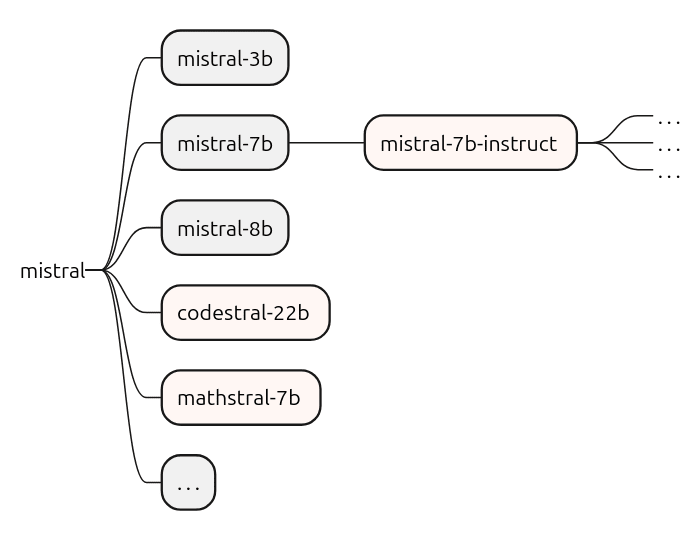
On the left-hand side, we have the model vendor, in this case, Mistral AI, which trains and distributes the foundational base models. Fine-tuned derivatives, such as mistral-7b-instruct, are then adapted for instruction-based use cases, responding to prompts in a structured, context-aware manner.
Another model family might look similar but target different objectives or architectures:
However, a “model” – whether base or fine-tuned – is not particularly useful on its own. It’s essentially a collection of learned weights: billions of numerical parameters, with no runtime context. What matters to developers is the inference stack, the combination of a trained model and an optimized runtime that makes inference possible. In the literature, the term “model” often refers to the complete model artifact, including the tokenizer, pre and post-processing components, and runtime format, e.g., PyTorch checkpoint, ONNX, and GGML.
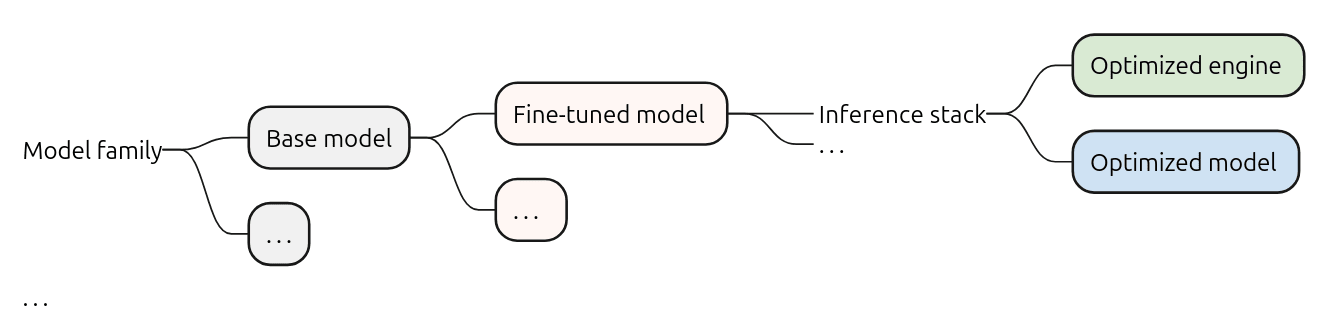
Inference stacks include inference engines, the software responsible for executing the model efficiently on specific hardware. Besides the weights of the pre-trained model, e.g. the weights of Qwen2.5 VL quantized at Q4_K, an engine will typically include the execution logic, optimizations to efficiently perform matrix multiplications and supporting subsystems. Examples include Nvidia’s TensorRT, Intel’s OpenVINO, Apache’s TVM, and vendor-specific runtimes for NPUs. Multiple stacks can exist for the same model, each tailored to different architectures or performance targets. These engines differ in supported features, kernel implementations, and hardware integration layers – reflecting differences in CPU, GPU, NPU, or accelerator capabilities.
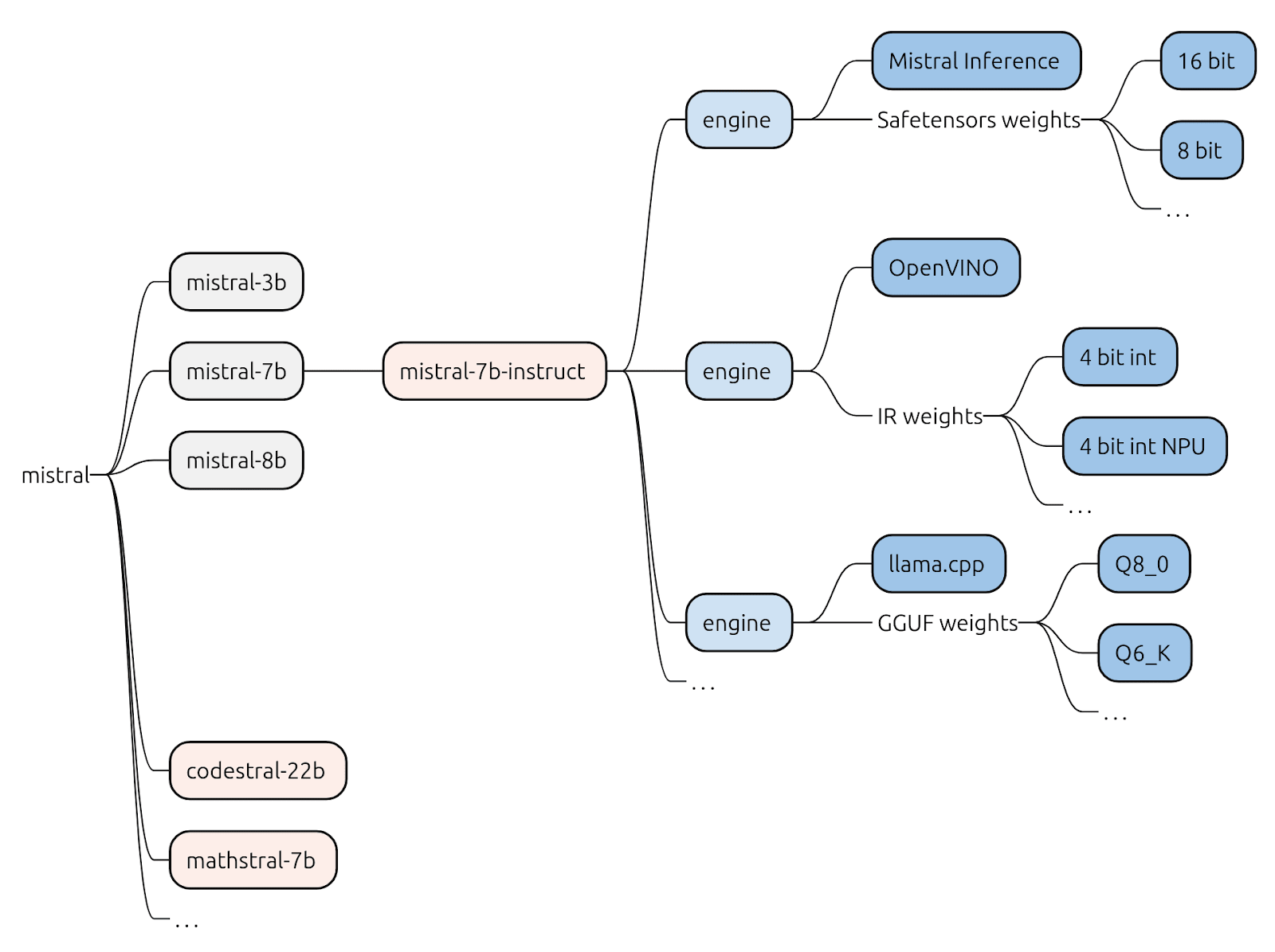
For instance, for a fine-tuned model such as mistral-7b-instruct, one might find multiple inference stacks:
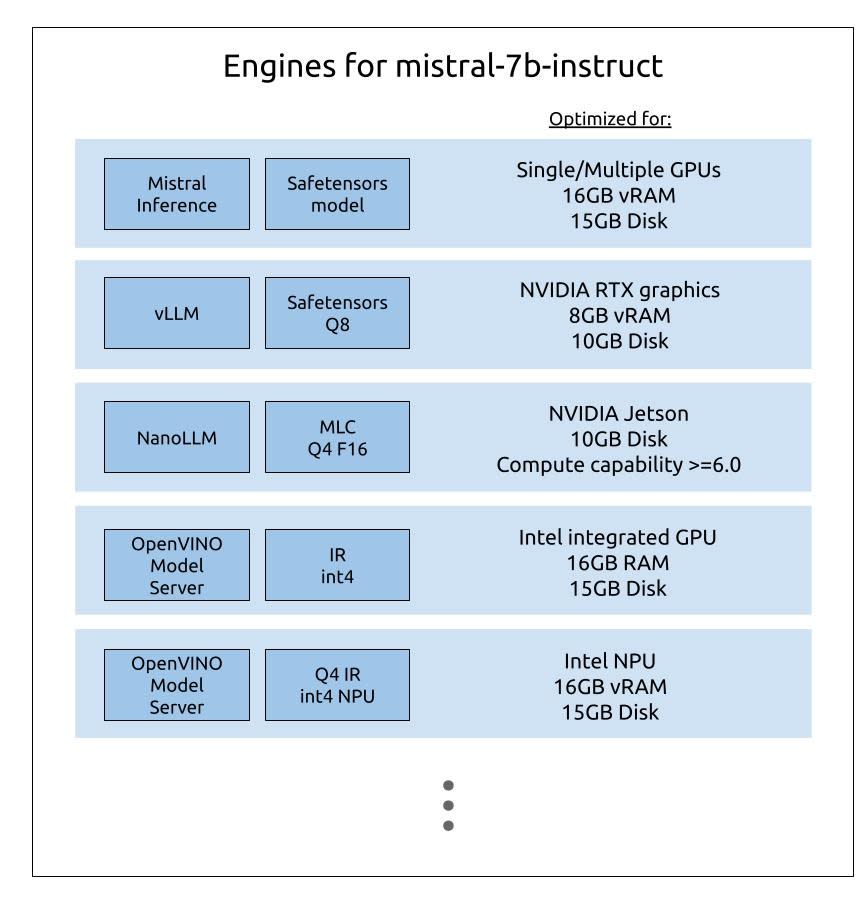
Optimizing hardware for inference
Running LLMs efficiently depends critically on the underlying hardware and available system resources. This is why optimized versions of fine-tuned models are often required. A common form of optimization is quantization, reducing the numerical precision of a model’s parameters (for example, converting 16-bit floating-point weights to 8-bit or 4-bit integers). Quantization reduces the model’s memory footprint and computational load, enabling faster inference or deployment on smaller devices, often with minimal degradation in accuracy.
Beyond quantization, optimization can be silicon-specific. Different hardware architectures, e.g. GPUs, TPUs, NPUs, or specialized AI accelerators, exhibit unique performance characteristics: compute density, memory bandwidth, and energy efficiency. Vendors exploit these characteristics through hardware-aware model variants, which are fine-tuned or compiled to maximize performance on their specific silicon.
For silicon vendors, demonstrating superior inference performance directly translates into market differentiation. Even marginal improvements – a 2% gain in throughput or latency on a leading LLM – can have significant implications when scaled across data centers or deployed at the edge.
This performance race fuels intense investment in AI model optimization across the hardware ecosystem. Each vendor aims to maximize effective TFLOPS and real-world inference efficiency. The result is an expanding landscape of hardware-optimized model variants, from aggressively quantized models that fit within strict memory limits to GPU-tuned builds exploiting tensor cores and parallel compute pipelines.
Furthermore, model packaging and runtime format affect deployability, as one needs optimized artefacts per target, e.g. TorchScript/ONNX for GPUs, vendor-compiled binaries for NPUs, GGML or int8 CPU builds for constrained devices.
As a consequence, developers building embedded AI apps are stuck dealing with API keys, per-token subscriptions, and apps that only work when connected to fast internet. Packaging and distributing AI-powered software is hard. Developers must contend with dozens of silicon types, hundreds of hardware configurations, and an ever-growing number of models and variants – while also managing dependencies, model updates, runtime engines, API servers, optimizations, and more.
Simplifying AI development: abstracting complexity away
Is it possible to abstract that complexity away? Today, developers build on Ubuntu without needing to think about the underlying hardware. The same principle should apply to AI: what if, in the future, a developer could simply code for DeepSeek, without worrying about selecting the optimal fine-tuned variant, choosing the right inference engine, or targeting a specific silicon architecture?
This is the challenge we set out for ourselves, bridging the gap between the potential of AI and its practical adoption. Our goal is to bring the right models directly into developers’ hands and make LLMs part of everyday software development
We envision a world where application developers can target an AI model, not a stack, and seamlessly use hardware-specific optimizations under the hood. To truly harness the potential of AI, developers shouldn’t have to worry about quantization levels, inference runtimes, or attaching API keys. They should simply develop against a consistent model interface.
Unfortunately, today’s AI ecosystem is still fragmented. Developer environments lack a standard packaging and distribution model, making AI deployment costly, inconsistent, and complex. Teams often spend significant time configuring, benchmarking, and tuning inference stacks for different accelerators, work that demands deep expertise and still leaves hardware underutilized.
This is why, through Canonical’s strong ecosystem partnerships, we introduced an abstraction layer that gives users access to develop using a known model while integrating the hardware-specific stacks. Last week, we announced the public beta release of AI models on Ubuntu 24.04 LTS, with DeepSeek R1 and Qwen 2.5 VL builds optimized for Intel and Ampere hardware. Developers can locally install those snaps pre-tuned for their silicon, without wrestling with dependencies or manual setup. Our snap approach enables development against a model’s standard API on Ubuntu, while relying on optimized builds engineered by Canonical, Intel, and Ampere.
Silicon-vendor optimizations will now be automatically included when detecting the hardware. For example, when installing the Qwen VL snap on an amd64 workstation, the system will automatically select the most suitable version – whether optimized for Intel integrated or discrete GPUs, Intel NPUs, Intel CPUs, or NVIDIA GPUs (with CUDA acceleration). Similarly, on arm64 systems using Ampere Altra/One processors, the version optimized for those CPUs will be used. If none of these optimizations match the hardware, Qwen VL will automatically fall back to a generic CPU engine to ensure compatibility.
Canonical’s silicon partnerships: planning for the future
As we saw, the performance of AI models is tightly bound to the silicon layer. Optimizing for silicon covers multiple layers, from reduced numeric precision, to operator fusion and kernel fusion, memory layout and tiling changes, and vendor-specific kernel implementations. The inference stack itself, from TensorRT, ONNX Runtime, OpenVINO/oneAPI, and vendor NPUs’ runtimes, materially affects latency, throughput and resource utilization. By working with silicon leaders, Canonical can now deliver robust, stable, locally optimized models that run efficiently on desktops, servers, and edge devices, reducing reliance on massive cloud GPU deployments, lowering costs and energy use, improving latency, and keeping sensitive data on-device. Each model can be installed with a single command, without manual setup or dependency management. Once installed, the snap automatically detects the underlying silicon, currently optimized for Intel CPUs, GPUs and NPUs, and Ampere CPUs, applying the most effective combination of inference engine and model variant.
With Ubuntu Core, Desktop and Server, we already provide a consistent OS experience to millions of developers across verticals and form factors. We are now eager to extend our collaborations with the silicon community and broader ecosystem, and are perfectly placed to enable AI models across the compute spectrum.

